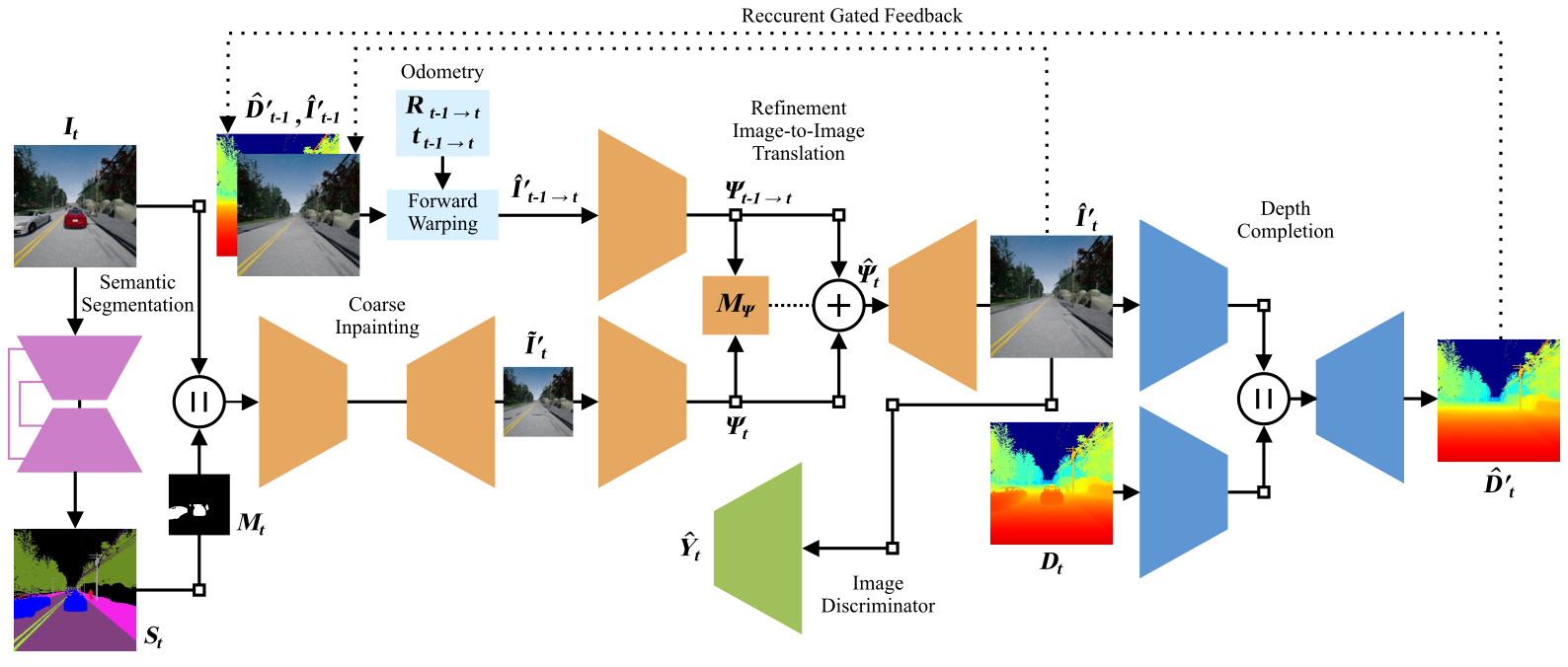
Dynamic objects have a significant impact on the robot's perception of the environment which degrades the performance of essential tasks such as localization and mapping. In this work, we address this problem by synthesizing plausible color, texture and geometry in regions occluded by dynamic objects. We propose the novel geometry-aware DynaFill architecture that follows a coarse-to-fine topology and incorporates our gated recurrent feedback mechanism to adaptively fuse information from previous timesteps. We optimize our architecture using adversarial training to synthesize fine realistic textures which enables it to hallucinate color and depth structure in occluded regions online in a spatially and temporally coherent manner, without relying on future frame information.
DynaFill Demo
Slide the white double arrow to the left or to the right to compare the dynamic object removal and inpainting by DynaFill.